![[アップデート] Amazon Redshift Zero-ETL統合のテーブルのrefresh intervalをサポートを試してみた](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-63f1274931b942e9a92e601c1127ad73/cfe87ec6d62fa2fc3c474ed4cb2f6c2e/amazon-redshift?w=3840&fm=webp)
[アップデート] Amazon Redshift Zero-ETL統合のテーブルのrefresh intervalをサポートを試してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
AWS事業本部コンサルティング部の石川です。最近、続々とZero-ETL統合が一般提供開始していますが、今日ご紹介するアップデートは、Zero-ETLでにおいて新たなに 「refresh interval」をサポート しました。この機能により、Amazon Redshiftへのデータレプリケーションの頻度をより柔軟にコントロールできるようになるアップデートです!
refresh interval機能とは
Amazon RedshiftのZero-ETL統合は、refresh interval機能によってデータの継続的なレプリケーションプロセスの開始タイミングを制御できます。リアルタイム性と処理負荷のバランスを取ることが可能になり、不必要に頻繁なデータ更新を避けることで、システムリソースをより効率的に使用できるようになります。
refresh intervalのデフォルト値と設定範囲
refresh intervalは、連携されるデータソースによって、デフォルト値や設定できる範囲が異なります。今後、Zero-ETL統合をサポートするデータベースが増えた場合は、Amazon Redshift - Database Developer Guide - ALTER DATABASEをご確認ください。
Aurora MySQL、Aurora PostgreSQL、RDS for MySQL
- デフォルト値: 0秒
- 設定範囲: 0〜432000秒(0秒〜5日)
Amazon DynamoDB
- デフォルト値: 900秒(15分)
- 設定範囲: 900〜432000秒(15分〜5日)
refresh intervalの設定方法
現在の設定値を確認するには、以下のSQL文を実行します。このクエリは、svv_integrationsビューから指定された統合IDに対するrefresh intervalの現在の設定値を返します。
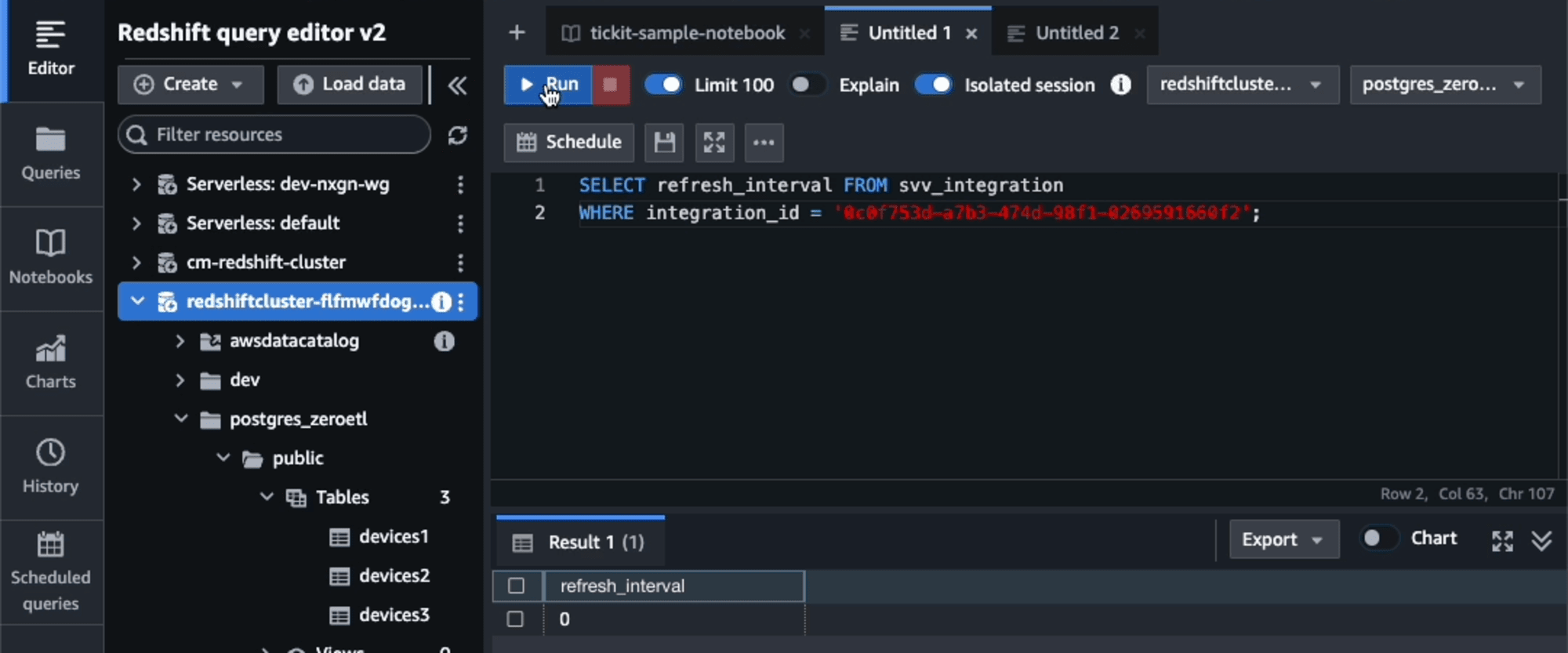
SELECT refresh_interval
FROM svv_integration
WHERE integration_id = 'integration_id';
設定値を変更するには、以下のSQL文を実行します。このクエリは、指定されたデータベースに対して更新間隔を600秒に設定します。
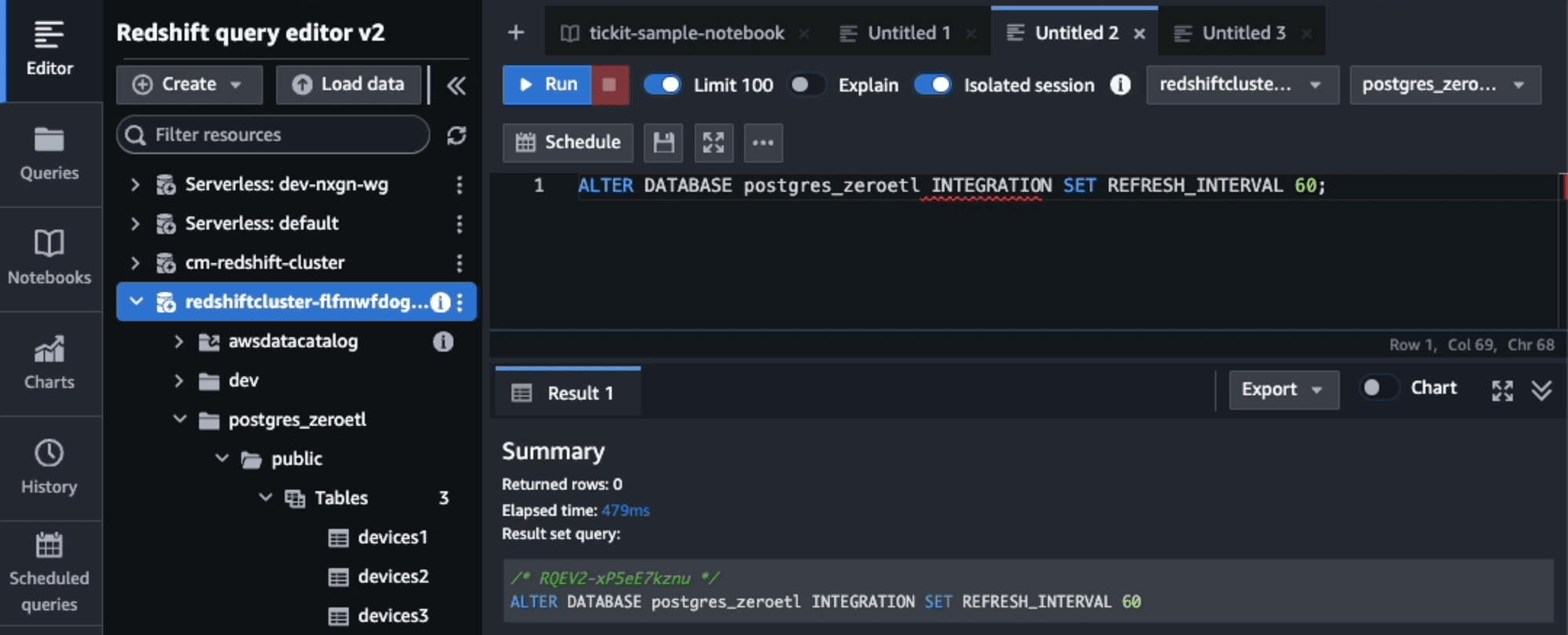
ALTER DATABASE sample_integration_db INTEGRATION SET REFRESH_INTERVAL 600;
refresh intervalの設定を試す
refresh intervalの設定変更(0秒から60秒へ)
現在の設定を確認します。デフォルトの0が設定されています。
refresh intervalに60秒を設定しました。
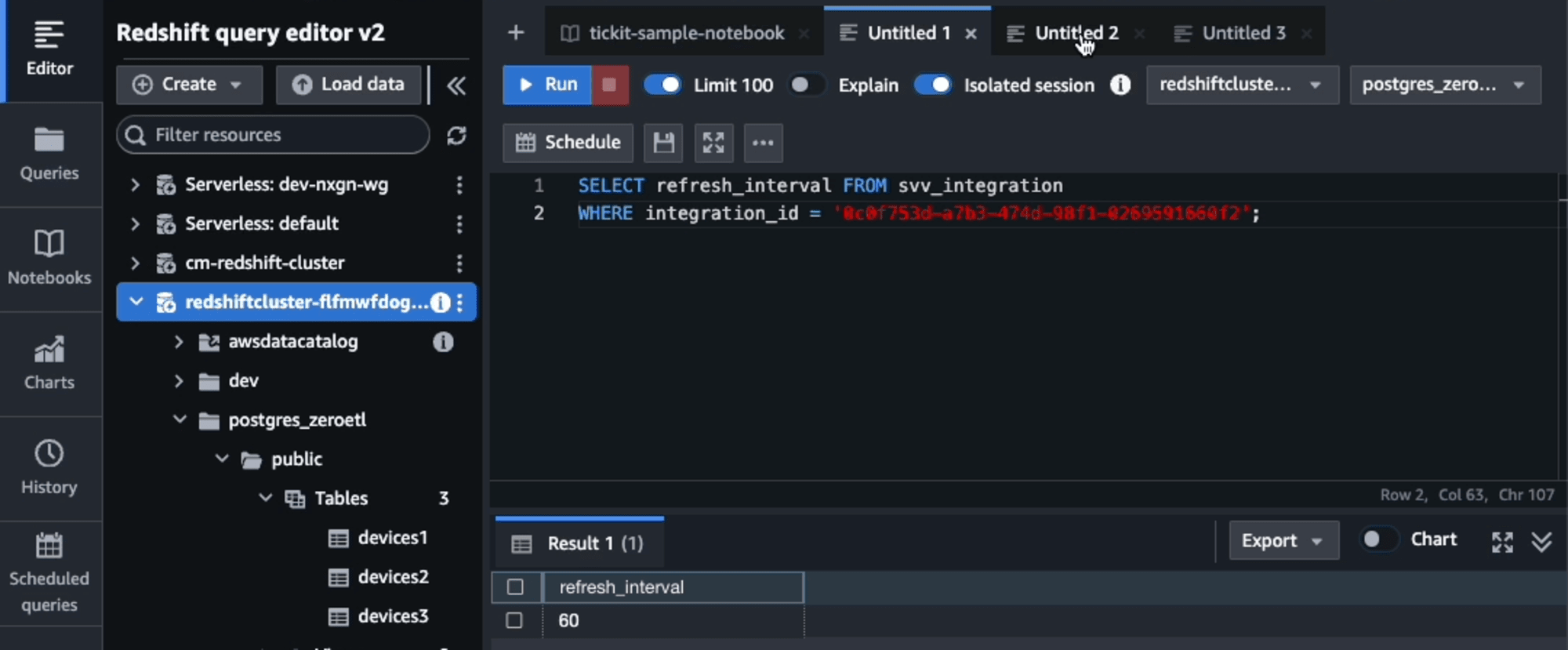
更新後の設定を確認すると、60秒に変更されたことが確認できました。設定と反映は数秒かかりました。
refresh intervalを60秒に変更後の動作確認
refresh intervalを0秒(デフォルト)の場合は、2〜3秒後にリプリケーションされます。今回は、refresh intervalを60秒に変更して、実際に何秒でリプリケーションするのかを確認します。
Aurora PostgreSQLから、約10秒間隔でレコードを順次追加します。

最初の1レコードは60秒を待たずに10秒未満で、Redshiftに連携されました。
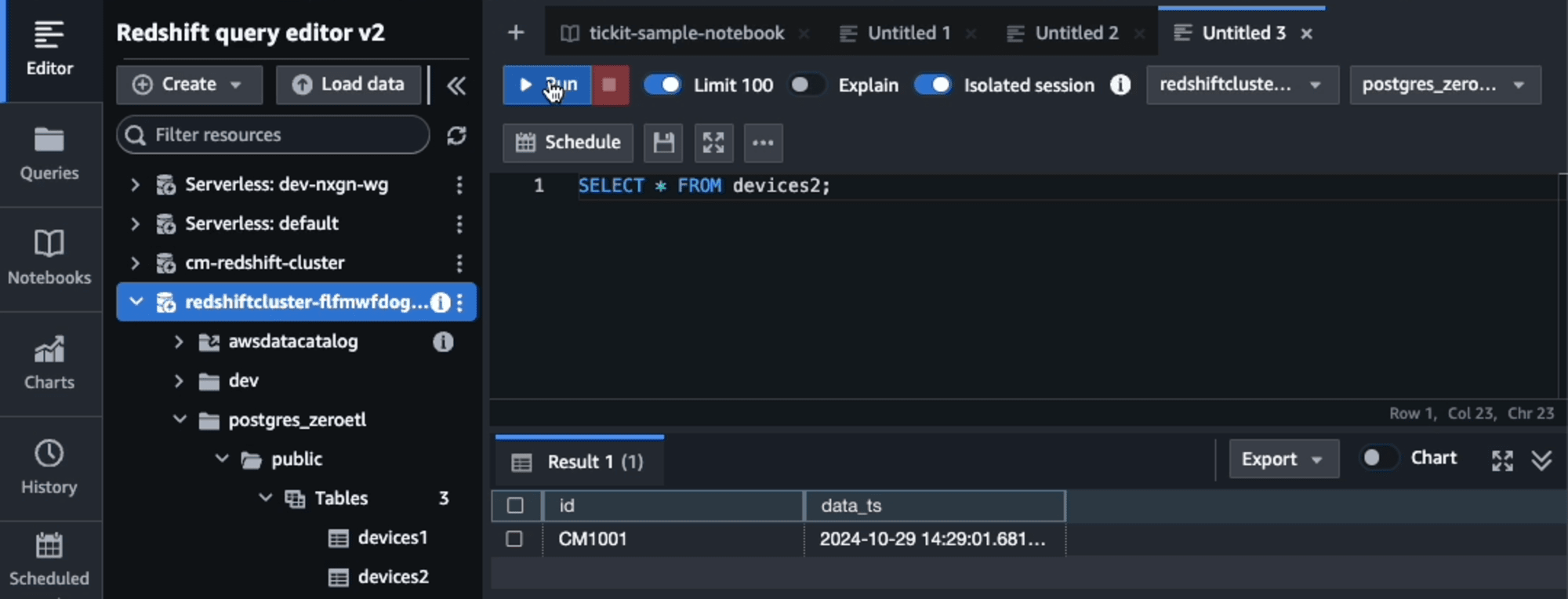
Aurora PostgreSQLに8レコードを追加した時点(70秒(10秒+60秒)経過)です。
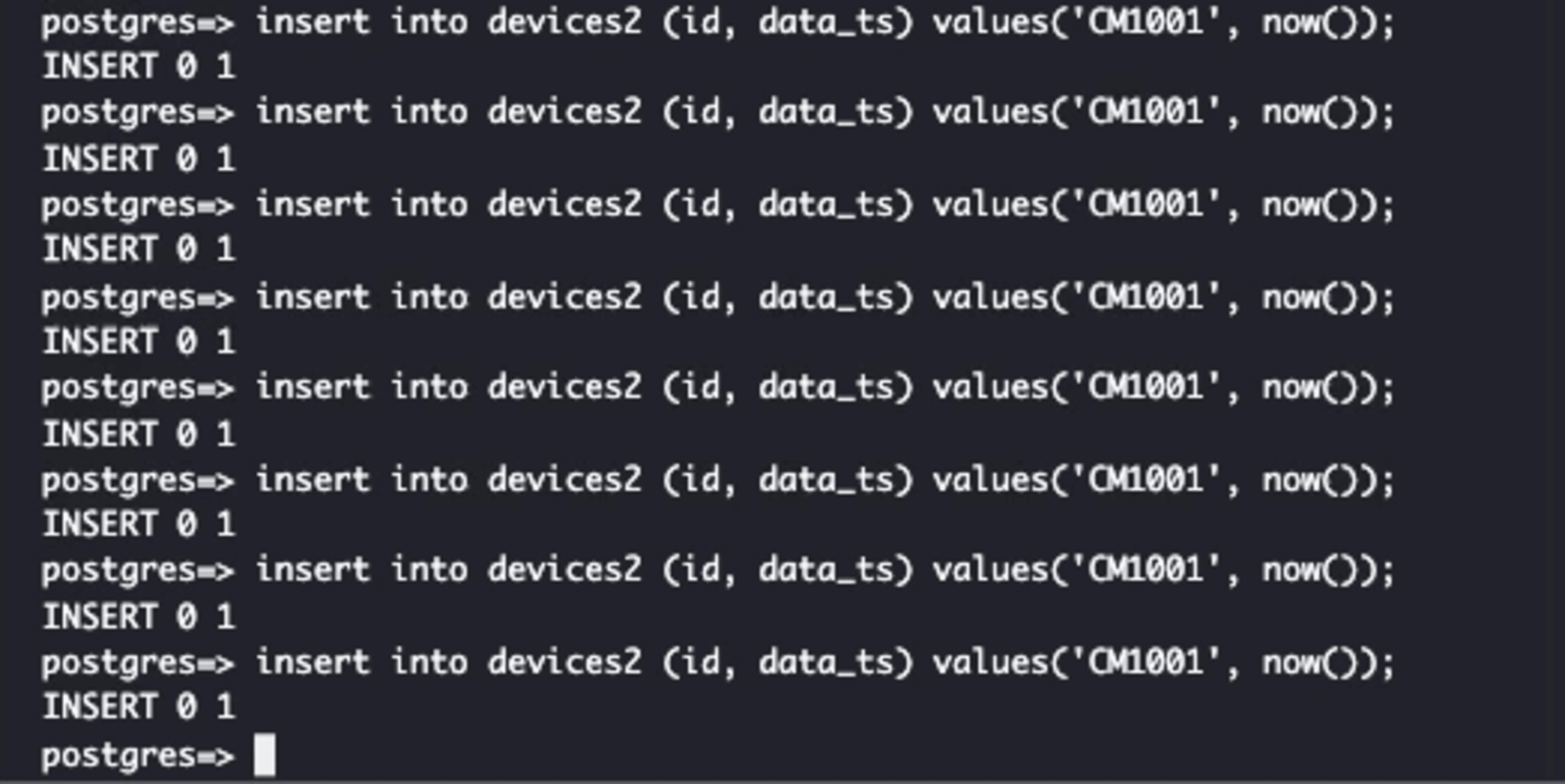
最初の2レコード以降は、前回から約60秒にまとめて6レコードRedshiftに連携されました。
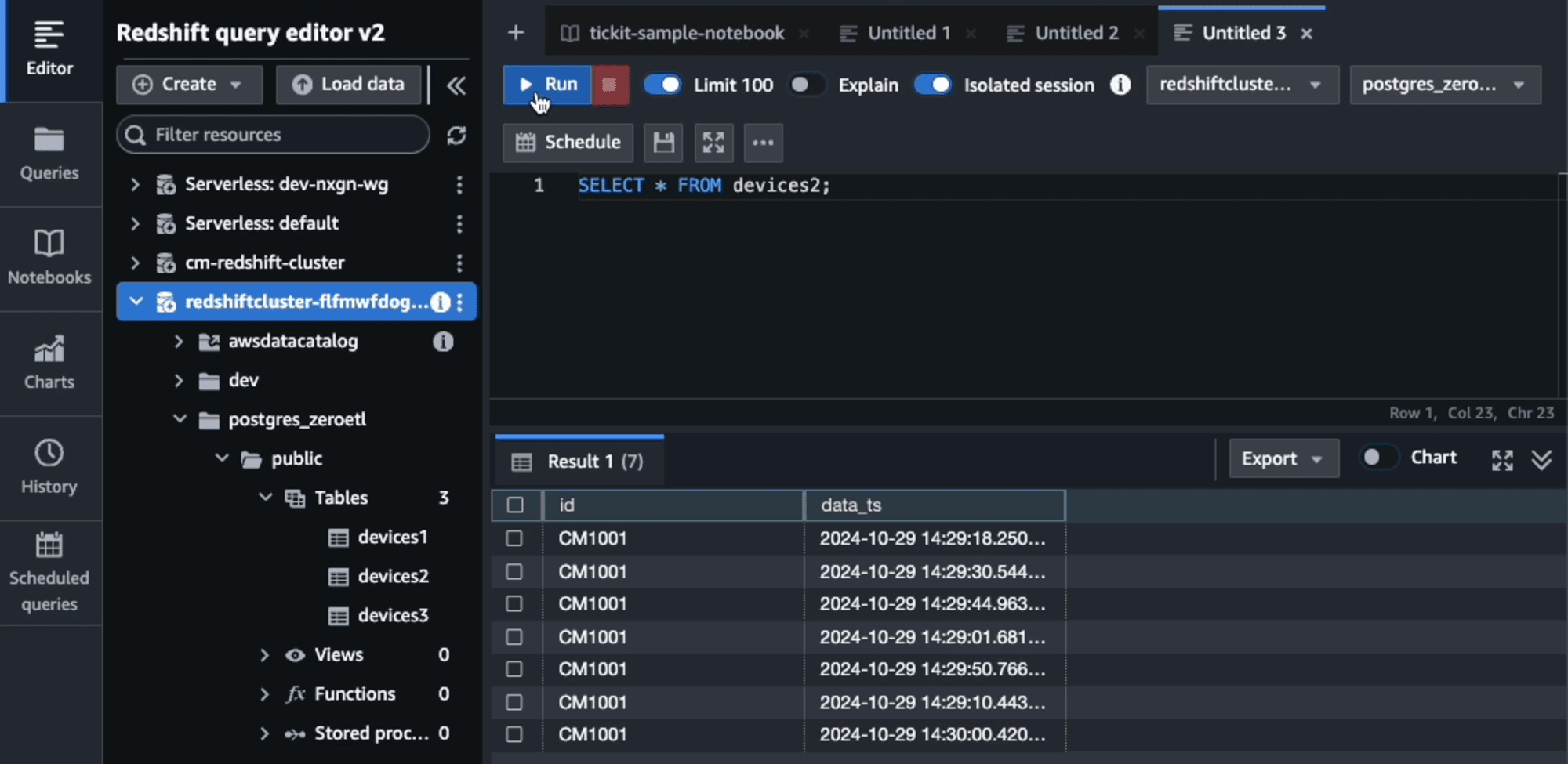
それ以降は、約60秒間隔で6レコードまとめてRedshiftに連携されることが確認できました。
テーブルの統計情報からもその様子が確認できました。
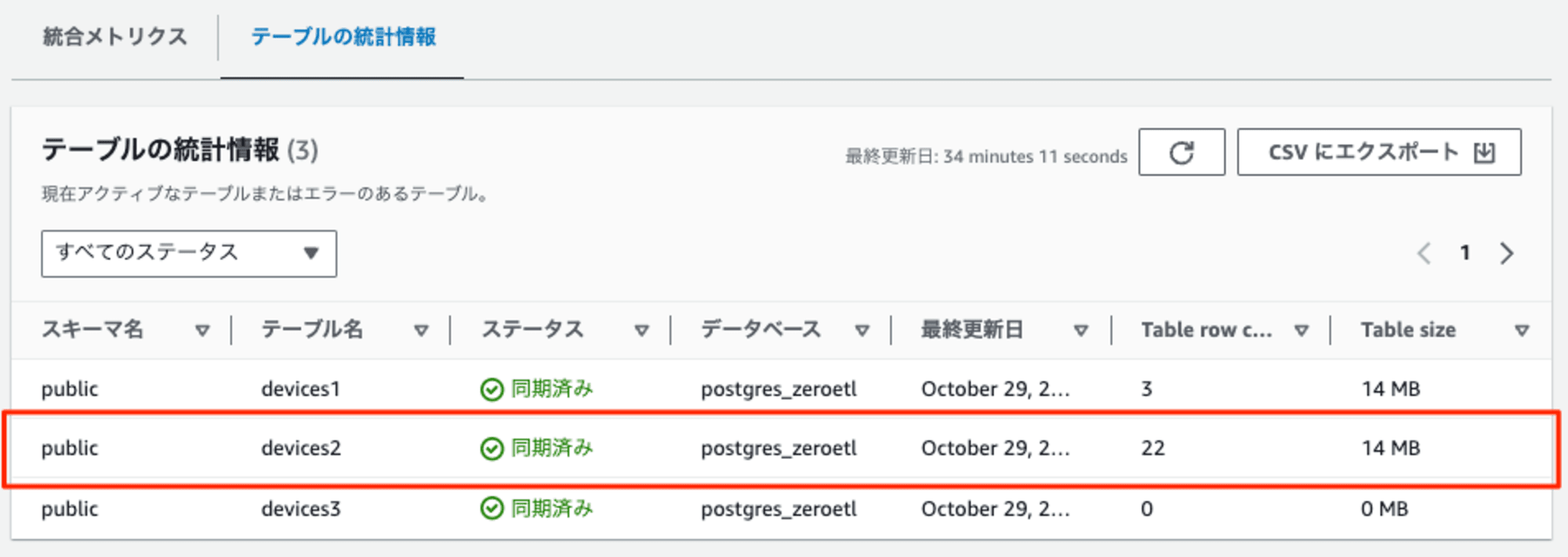
初回は例外的にすぐにレプリケーションされますが、それ以降は設定したrefresh intervalに従い、レコードが連携されるようです。
最後に
これまでのZero-ETL統合では、refresh intervalが0でした。遅延することなくレプリケーションされることは使い勝手が良いのですが、頻繁なデータレプリケーションによって生じる課題もありました。例えば、Amazon Redshift Serverlessの場合、データレプリケーションによって60秒の最小課金時間が頻繁に発生すると、総コストが増加する可能性がありました。データ量がそれほど多くない場合、1時間(3600秒)ごとに同期するように変更することでコストが1/60で済む可能性があります。
このようにrefresh interval機能の導入により、データの鮮度、システムパフォーマンス、およびコストの間でより細かいバランスを取ることができるようになりました。これは特に大規模なデータセットや複雑なデータパイプラインを扱うユースケースでは重要になりますので、ぜひご検討ください。
合わせて読みたい









